
Abstract
Text-guided diffusion models (TDMs) are widely applied but can fail unexpectedly. Common failures include: (i) natural-looking text prompts generating images with the wrong content, or (ii) different random samples of the latent variables that generate vastly different, and even unrelated, outputs despite being conditioned on the same text prompt. In this work, we aim to study and understand the failure modes of TDMs in more detail. To achieve this, we propose SAGE, the first adversarial search method on TDMs that systematically explores the discrete prompt space and the high-dimensional latent space, to automatically discover undesirable behaviors and failure cases in image generation. We use image classifiers as surrogate loss functions during searching, and employ human inspections to validate the identified failures. For the first time, our method enables efficient exploration of both the discrete and intricate human language space and the challenging latent space, overcoming the gradient vanishing problem. Then, we demonstrate the effectiveness of SAGE on five widely used generative models and reveal four typical failure modes that have not been systematically studied before: (1) We find a variety of natural text prompts that generate images failing to capture the semantics of input texts. We further discuss the underlying causes and potential solutions based on the results. (2) We find regions in the latent space that lead to distorted images independent of the text prompt, suggesting that parts of the latent space are not well-structured. (3) We also find latent samples that result in natural-looking images unrelated to the text prompt, implying a possible misalignment between the latent and prompt spaces. (4) By appending a single adversarial token embedding to any input prompts, we can generate a variety of specified target objects, with minimal impact on CLIP scores, demonstrating the fragility of language representations.
Method

Given a text-guided generative model G, we want to automatically find natural text prompts p or non-outlier latent variables z that generate failure images. We formulate it as an adversarial optimization process. A gradient-guided search policy P is proposed to enable efficient search over the discrete prompt space, and the residual connection is used to back-propagate the gradient from outputs I to the inputs of latent variable. Finally, an ensemble of discriminative models is used to obtain a robust discriminator D to find true failures of the generative model G.
Typical Failure Modes
I. Natural Text Prompts that are Unintelligible for Diffusion Models
We find a large number of concise text prompts (at most 15 words) that are natural and easily understood by humans but not by the SOTA diffusion models. Current models still struggle to grasp and describe certain linguistic representations. We manually summarize the key features and categorize them into ten distinct types, based on the underlying causes. Current models are good at understanding objects, but may be confused by specific actions ('fighting' in a), and may struggle to understand the relationship between nouns and verbs (b), nouns and adjectives (c), subjects and objects (d), and words with salient features (e). In addition, they often do not comprehend compositions (f), numbers (g), parts (h), viewpoints (i), and fractions (j).

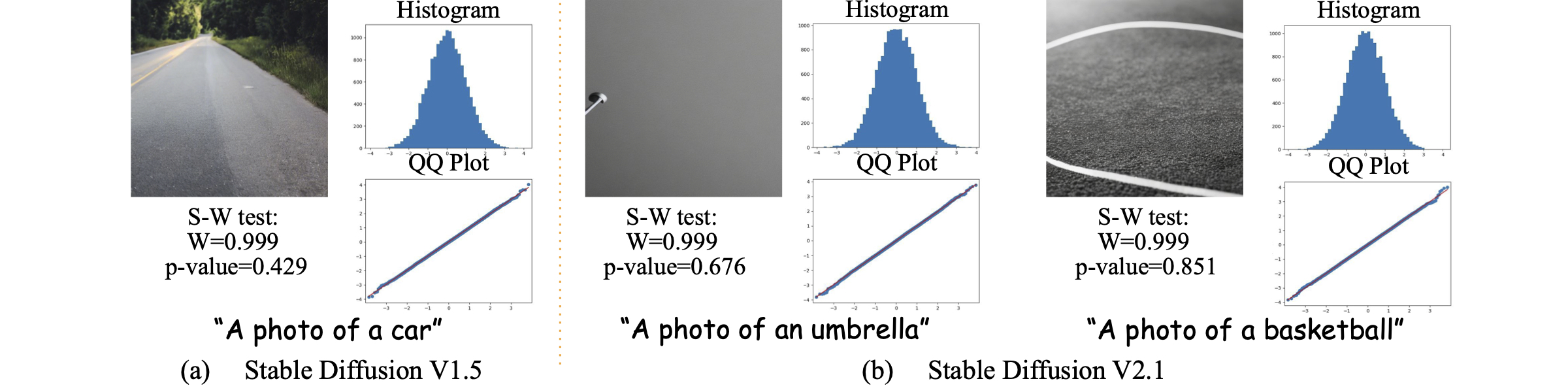
II. Latent Samples that Lead to Distorted Images
We find samples/regions in the latent space that consistently lead to distorted images under various commonly used prompts, implying that parts of the latent space are not well-structured. We also show that both generative models and discriminative models have representation biases that differ from those of human vision.
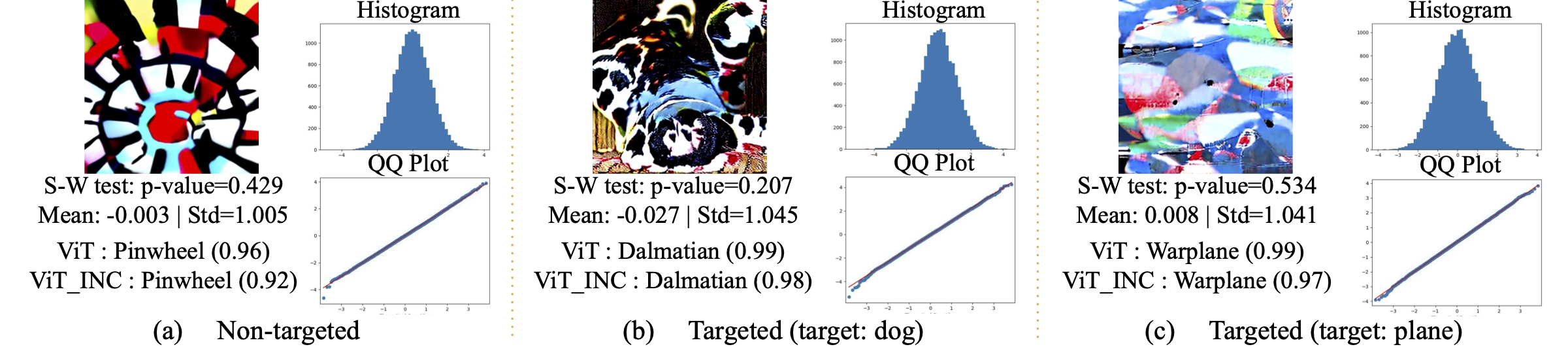
III. Latent Samples that Do Not Depict the Key Object but Correlated Background
We find latent samples that generate objects commonly associated with the key object, rather than generating the key object class itself. It indicates a partial misalignment between the latent space and the prompt space. Furthermore, we demonstrate the correlation between this misalignment and the stability of diffusion models.
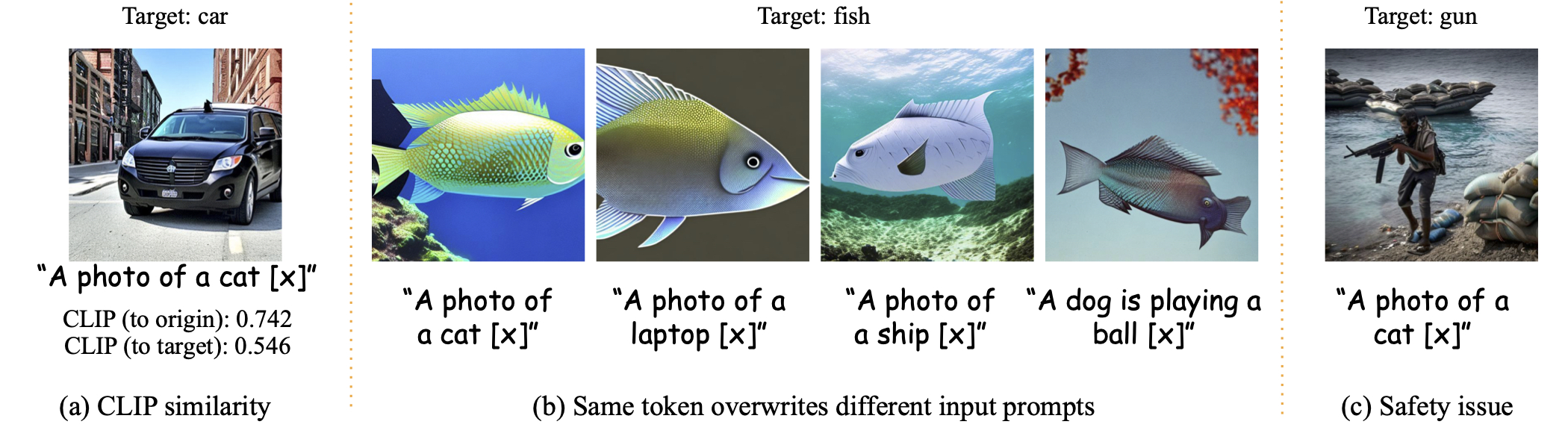
IV. Universal Token Embeddings that Overwrite the Input Prompts
We also find adversarial token embeddings, which only slightly change the CLIP score, but cause the diffusion model to produce irrelevant images. These adversarial embeddings are universal in the sense that they cause failures across a variety of input prompts. It also reveals potential safety concerns.
More Results
We provide additional representative text prompts that diffusion models cannot understand.





Bibtex